We are currently working with a number of UK water companies on projects which involve building DMA models to conduct network analysis. For this task, we required a generic system which could ingest client GIS data and output functional hydraulic network models. Key requirements included that data transformation and cleansing be as automated as possible, and that the system be able to provide a spatial view of the data. This blog post explores the two main options considered for the database technology on which to base the system and aims to provide some insight into the relative strengths and weaknesses of PostgreSQL vs MySQL databases for hydraulic network modelling purposes.
Problem
The role of ‘model build’ software is to map and transform network data from one or (usually) more sources into a format which can be read by a solver. The caveat is that even the most diligently maintained GIS will include countless inconsistencies and data anomalies, owing to the collaborative nature of its maintenance and the sheer volume of data.
These anomalies must be fixed before the model can be successfully simulated and can be very time-consuming to diagnose and rectify manually. Therefore, there are efficiency savings to be made by developing automated routines to detect and resolve as many of these anomalies as possible, and flag for engineer-review only those which cannot be solved without human intervention.
One of the most prevalent anomalies in network data is issues with connectivity between assets, for example a valve may appear to be on a pipe but is actually ‘floating’ in space and not connected in to the network. In fact, the majority of anomalies and/or their resolutions involve some spatial consideration. When defining the problem, it’s desirable that the system be able to provide a spatial view of the data, but essential that spatial queries and logic can be utilised to write the data cleansing procedures.
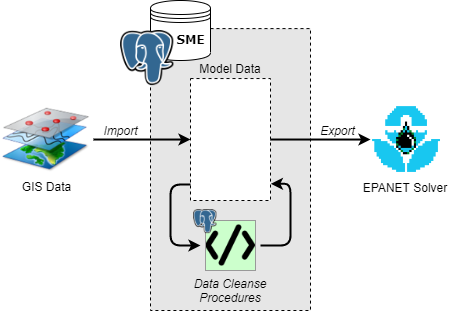
A simplified conceptual view of the data flow through the system is illustrated in Figure 1.
Figure 1: Simplified data flow diagram for transforming GIS network data to hydraulic model networks
Options
Based on prior experience and our initial research, two database technologies were considered for the implementation; PostgreSQL and MySQL. There are some excellent articles available online which compare and contrast these for general-purpose implementations, whereas the appraisal given here is specific to their suitability for network modelling data.
Complexity vs simplicity
In short, MySQL is excellent for simple data models and queries, and is easy for those with little DBMS experience to adapt to. The basic version of MySQL is free and technically open-source, but it is provided by Oracle who offer proprietary modules to extend its capabilities.
PostgreSQL is free, fully open-source and user extensible. Through the PostGIS extension, it is capable of advanced spatial functionality. While it is more complex, the documentation and community support are excellent and users familiar with DBMS concepts should have little trouble finding their way.
Spatial data
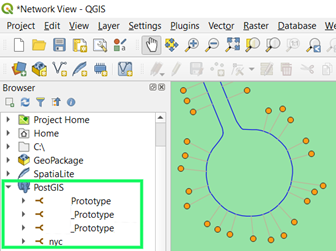
The major advantage of PostgreSQL for this solution is the spatial support through PostGIS. The tutorial provides an excellent introduction to its capabilities without overwhelming and should provide the skills with which one can begin to write their own spatial queries and procedures which make use of them. It is also strongly supported by the free open-source QGIS software (Figure 2), which we have adopted as part of our standard software suite. This is immensely helpful in terms of data visualisation for reference, troubleshooting and displaying analysis results.
Figure 2: PostGIS database support in QGIS
While some spatial capabilities have been developed for MySQL these are relatively in their early stages compared to PostGIS. Support for managing multiple SRIDs (spatial reference system IDs) was only added in 2018 and some key performance features, such as K-nearest neighbour (KNN) searches, are missing.
Chosen solution
We were able to utilise the performance of PostgreSQL spatial queries in the implementation of our automated data cleansing routines. As mentioned earlier, ‘floating’ assets are a typical and widespread problem when building model networks. Therefore, a fast method is required to identify and resolve all such issues.
Our procedures to resolve ‘floating’ assets (and also associate properties to pipes) use a custom function get_closest_pipe_to_point(p), which was written using K-nearest neighbour searching. An excerpt is shown in Figure 3. The index-based bounding box distance operator <-> is used in the blue subquery (closest_candidates) to quickly approximate the closest 10 pipes and the inbuilt ST_Distance(geom1, geom2) function is then used to accurately calculate the distance of the point to each of these pipes and identify the closest (red). This ‘shortlisting’ method offers great performance benefits and would not be possible in MySQL, where it would be necessary to calculate the accurate distance to all pipes before identifying the closest.
Figure 3: Implementation of KNN search in get_closest_pipe_to_point(p) function
Conclusion
MySQL’s simplicity and accessibility makes it an ideal option for many simpler data models and when spatial functionality is not essential. For this application concerning network model data, PostgreSQL has proved to be extremely powerful and versatile. We have been impressed with the excellent documentation, tutorials and community support and are excited to continue to learn about how PostgreSQL can be used to streamline our business processes.