Many of our recent projects involve the storage and use of flow and pressure data recorded on the water network. As our projects have grown, so have our database storage needs. We noticed we were experiencing a steady but consistent decline in query performance, particularly when accessing data for analysis from our time series repositories.
The problem
Flow and pressure data is usually recorded at 15-minute intervals on a water network. Our Dynamo project in Severn Trent Water involved the deployment and maintenance of over 6000 pressure loggers in over 500 DMAs. Add in the existing flow and pressure data for these DMAs, including customer logging, and this adds up to almost 10,000 sites in total. With 10,000 sites recording 96 times a day, we are close to a million new rows of data per day.
Furthermore, as we have started to roll out Paradigm, which involves in-depth time series analysis of historical DMA net flow data, we have been experiencing data sets of hundreds of millions and even billions of rows for our biggest clients.
Looking at both these scenarios, it was becoming increasingly apparent that we needed to improve and optimise our data storage methods.
The solution
Usually, when we are looking to improve query performance on large database tables, we tend to employ the use of indexes. Indexes are data structures used to help retrieve data quicker and are extremely effective. Think how useful the index at the end of a 1000 paged textbook is when looking for a particular topic, as opposed to turning every page one by one looking for that topic. However, when storing time series data for flow and pressure, the table structure for this data tends to be relatively simple and generally only consists of three core fields; a location reference, a timestamp, and the reading at that timestamp. We had initially started by creating indexes on the location and timestamp fields. Whilst this was extremely effective to begin with, we have since seen a steady rate of decline as the database tables have increased in size. Enter partitioning.
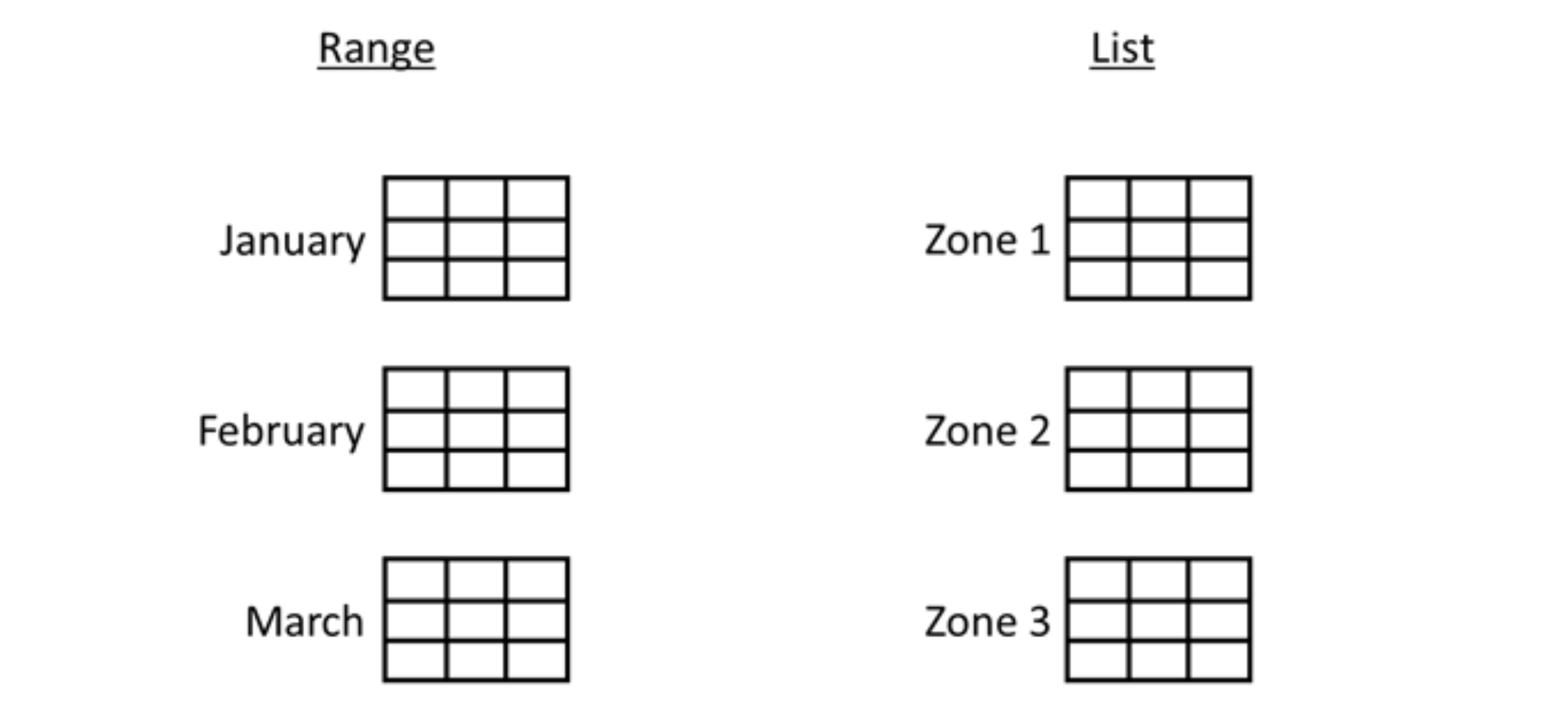
Partitioning refers to splitting what is one large table into many smaller physical ones. Indexes and partitions are not mutually exclusive and we believed that implementing a blend of partitions and indexes would provide us with the best solution for our use case.
As well as improved performance, partitioning also provides the following benefits:
- Security – sensitive and insensitive data can be separated into different partitions with their own security rules.
- Scalability – partitions can be split onto different servers removing any limitations by keeping a single database system on just one server.
- Management & maintenance – partitions can be fine tuned and managed to maximise operational efficiency and minimise cost.
- Availability – separating data across multiple servers avoids a single point of failure.
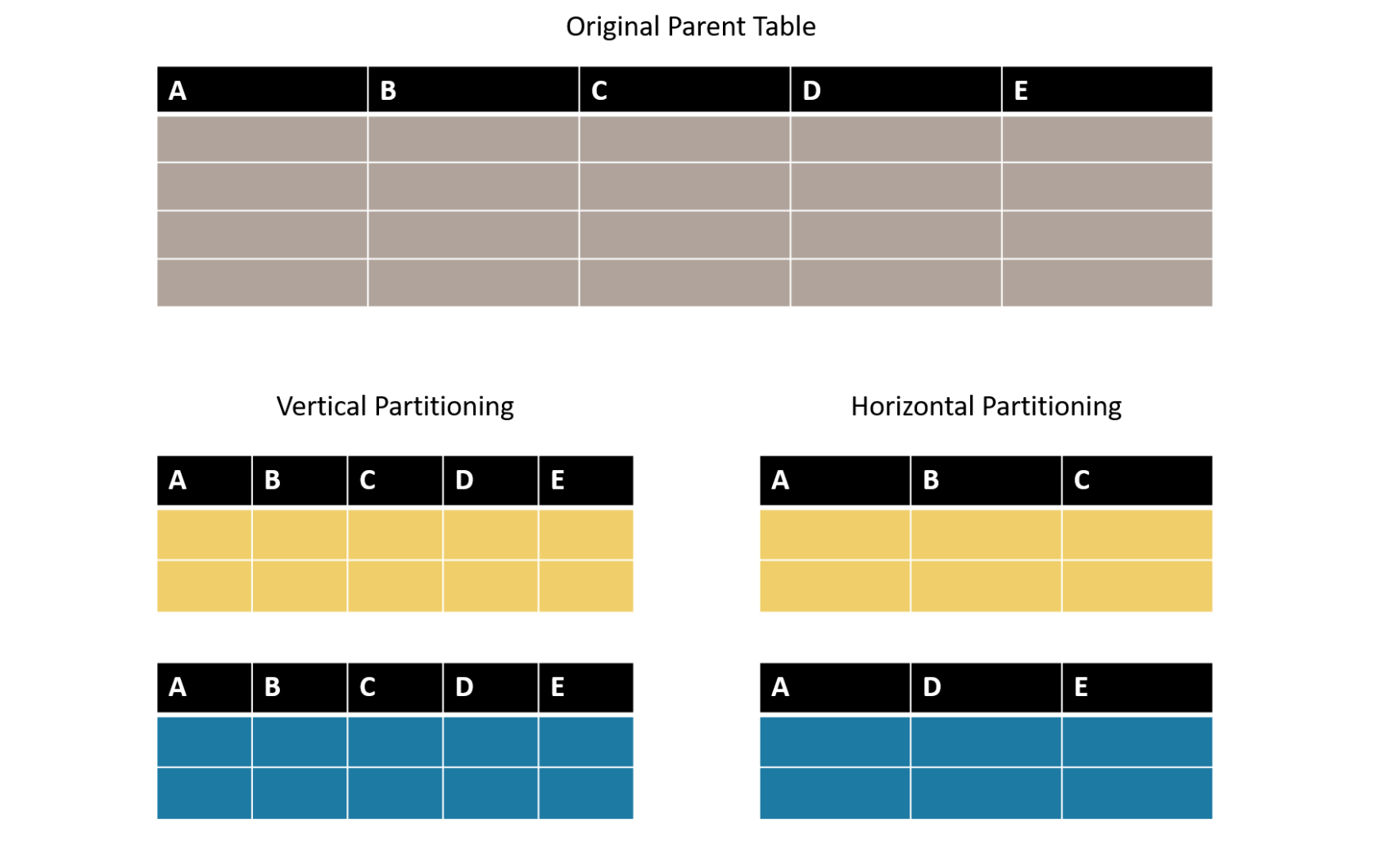
Partitioning on a large database table can either be vertical or horizontal. Vertical partitioning involves splitting rows from one large parent table into many ‘child’ tables. Horizontal partitioning involves splitting the columns in a large table and storing them in multiple tables.